上一篇: Part 2 RR调度周转、等待时间等的统计 第一篇: Part 1 xv6调度代码讲解
TODO3: 实现优先级调度算法
基于优先级的调度算法是一类算法,基本思想是为每一个进程赋予不同的优先级,在调度时优先选择优先级最高的进程来调度。优先级调度有许多种,大致可以分为:
-
非抢占式的优先级调度:
非抢占式的优先级调度算法中,每个进程只在初始时赋予一个优先级,在运行过程中不会被改变。每一次重新调度时,选择最高优先级的一个进程,将它运行完毕,然后再选择另外一个进程开始运行。一个进程在运行过程中如果有更高优先级的进程到来,它不会被打断,只是将该进程放到等待队列的队首。
xv6是开启抢占的,进程会被时钟中断打断,然后调度器选择另外一个进程(如果有的话)来代替它。
-
抢占式优先级调度:
抢占式优先级调度中,如果进程运行过程有更高优先级的进程到来,当它运行完这个时间片,就会被抢占。进程被赋予一个初始优先级,但这个优先级是可变的。具体的实现也有多种:
-
静态优先级调度:
静态优先级调度指的是进程最初有一个优先级,运行过程中可以通过系统调用改变这个优先级,但是不会随着等待时间或运行时间的增加而自动改变。
-
动态优先级调度:
进程最初被指定一个优先级,同样也可以通过系统调用改变。为了惩罚执行时间较长的进程,优先级会随着运行时间增加而逐渐降低。
-
多级反馈队列调度:
在系统中设置每个优先级对应的等待队列,进程初始化时进入某个队列。调度时,首先从最高优先级队列中找进程,只有当更高优先级队列为空时,才会调度某个低优先级队列中的进程。 同一个优先级的进程按FCFS调度。
多级反馈队列也有不同的实现。静态实现时,进程优先级不在运行过程中自动改变;动态实现时,可以让进程每运行完k个时间片,就下降到低一级的等待队列,一段时间后,再将进程提高到最高优先级。这样,既可以充分考虑IO-bound、CPU-bound进程的不同特性,又考虑到进程运行过程中IO-bound到CPU-bound的动态转变,减少进程饥饿的发生。
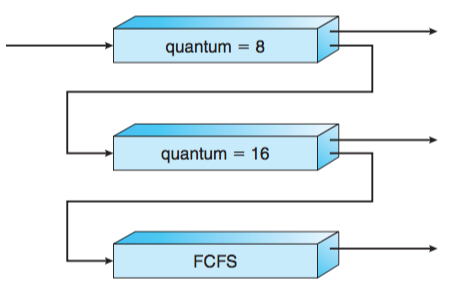
-
我将实现静态优先级调度和静态的多级反馈队列调度。
静态优先级调度
静态优先级调度是为每个进程赋予一个初始优先级,用户可以指定优先级。在每次重新调度时,遍历整个进程表,找到状态为RUNNABLE且优先级最高的进程来运行。
优先级的范围是[1,4], 数字越低代表优先级越高。
首先为进程添加priority变量:
1 | |
优先级调度的一个问题是,如何决定进程初始化时的优先级。初始化时的优先级也是系统进程的优先级,这个优先级不能太高,否则会让用户进程响应和等待的时间过长;但也不能太低,否则当用户需要某个内核进程的服务时,等待时间也会太长。这里,先将初始优先级设置为2. 在allocproc()中,进程初始化时:
1 | |
新的scheduler函数,在内层for循环中,再遍历整个进程表,用phigh保存目前为止优先级最高的进程。
1 | |
调度器的内层循环用指针p遍历整个进程表,本来每一次找到一个RUNNABLE进程,就切换到该进程。 用priority算法,每次调度一个进程后返回调度器时,p指向下一个RUNNABLE进程,phigh首先指向这个进程,然后遍历整个进程表,如果有更高级的进程,phigh会指向接下来第一个优先级最高的进程;如果没有,则下一个进程就是表中下一个可执行进程。
实现系统调用set_priority:
1 | |
把它封装好之后,修改RRsta.c, 加入set_priority:
1 | |
在内核中,添加一些额外的输出来验证算法实现的正确性。重新编译内核,然后执行priority_sta.c, fork 4个进程:
1 | |
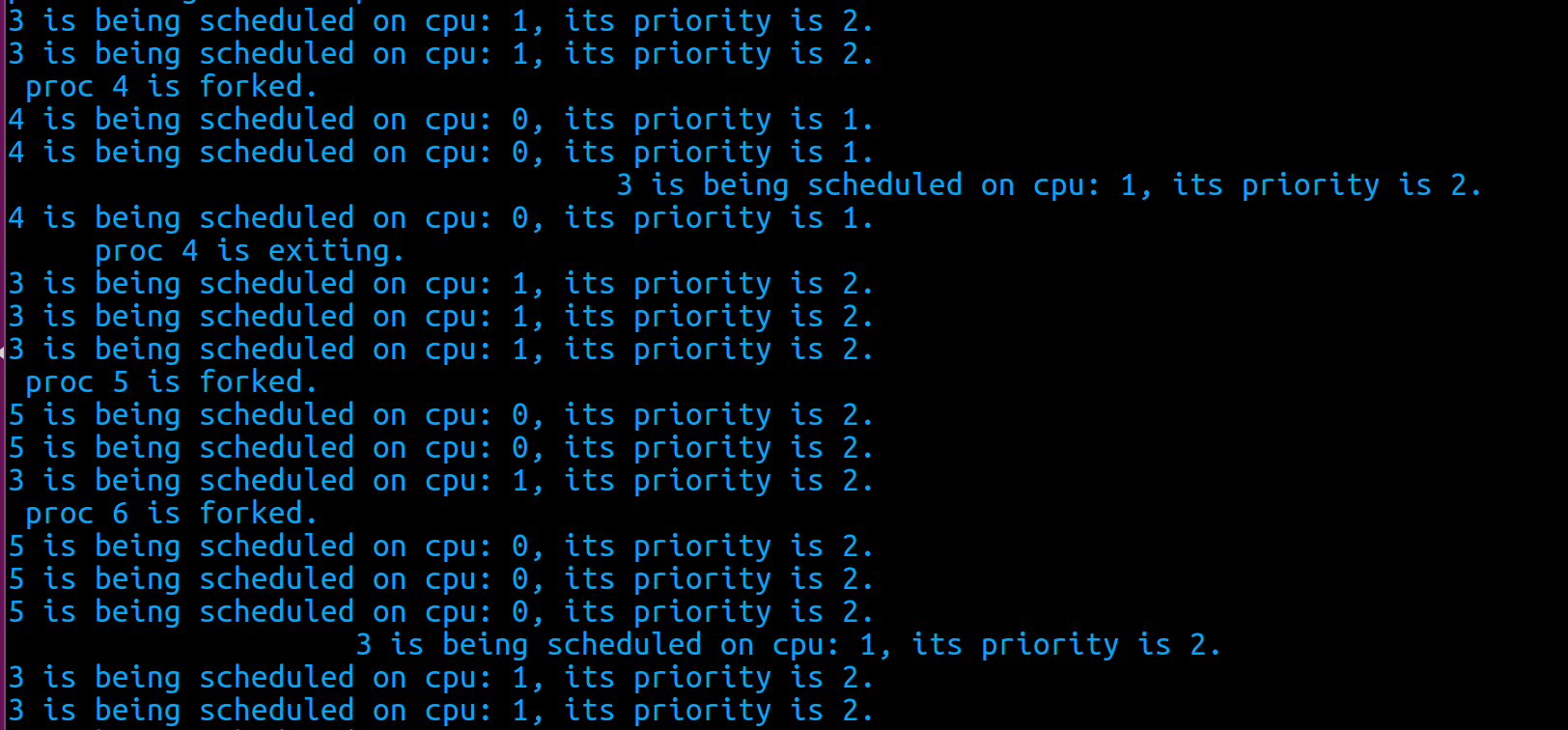
pid为3的进程是父进程,子进程的pid分别为4, 5, 6, 7,创建后set_priority, 使它们的优先级分别为1, 2, 3, 4;进程的初始优先级被设置为2.
当进程4被创建,并设置优先级为1之后,它是系统中优先级最高的进程,正确情况下会一直运行直到结束(除非它进入休眠,或者有同样优先级为1的进程到来);因为有两个cpu,进程3可以在另一个cpu上调度,继续创建进程5,6. 这时,进程4已经结束,系统中有3,5, 6三个进程,但正确情况下只有3和5可以被调度,6必须等待直到3和5不是RUNNING或RUNNABLE状态。
从这段程序的输出来看,目前的调度都是正确的。进程6一直没有被调度,直到进程3进入休眠:
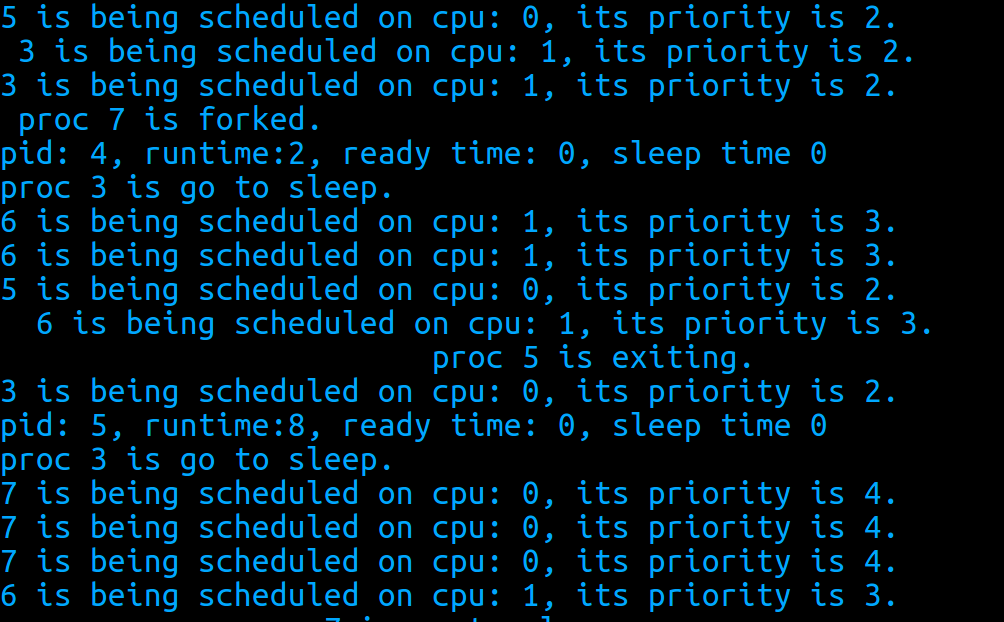
进程3创建了进程7(最后一个子进程)之后,它就进入休眠等待所有子进程结束。这时进程6被第一次调度,而直到进程5结束,系统只剩下3,6,7时,在进程3休眠时进程7才可被调度。
统计所有进程的运行情况:
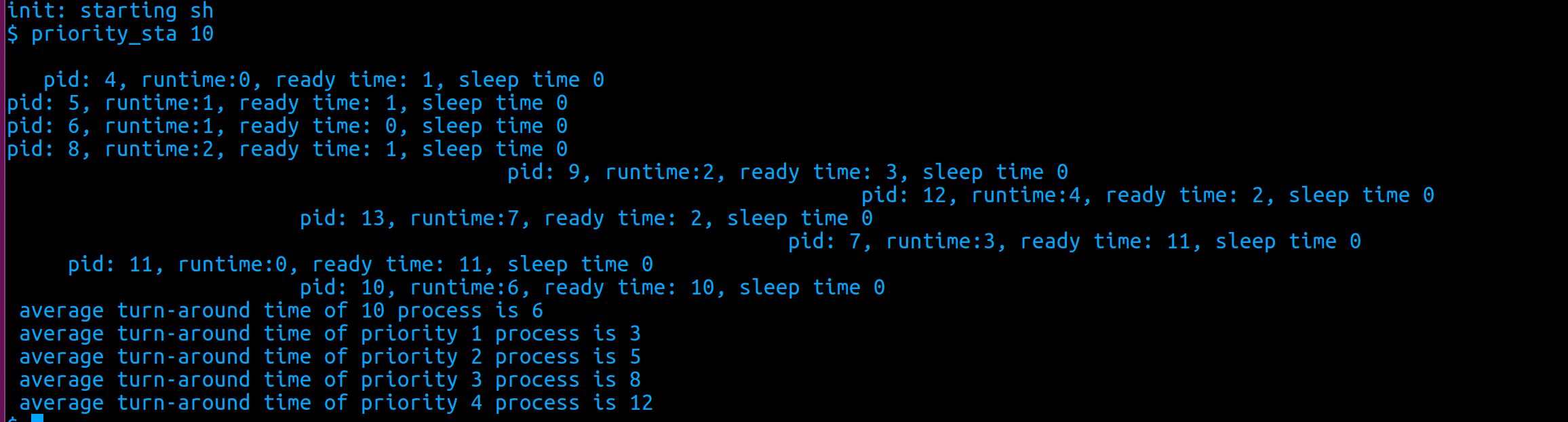
优先级越高的进程平均周转时间越长。从图中可以看出,进程的运行时间相差不大,而优先级最低的进程(7,11)明显等待时间比其他进程要长很多(11)。但从单个进程来看,不一定优先级越低进程周转时间越长,例如进程10(优先级为3)的周转时间就比进程11(优先级为4)长很多,这是因为进程11到达更晚,且它到达时系统中更高优先级的进程几乎已经都执行结束。
静态多级反馈队列
静态多级反馈其实跟上面的静态优先级调度类似,但是它使用了多级队列的方法,使优先级相同的进程能够按照FCFS来调度。静态优先级调度则不一定是先来先服务的,因为它是遍历整个进程表找最高优先级的进程,这样,当pid序号在前的进程退出被回收之后,前面就会出现空槽,更新创建的进程反而会比老的进程pid序号更低,更先被调度。
实现多级反馈队列,首先要为每个优先级定义对应的等待队列。等待队列由一个proc结构体的指针数组来表示,考虑到进队和出队的动作一般发生在进程的优先级发生改变或者状态改变的时候,都会持有ptable.lock,则访问等待队列已经可以保证互斥。因此可以省略等待队列的锁。同时,用变量size来表示等待队列目前的大小,也就是最后一个进程的下标。
1 | |
内核开始时,要初始化4条优先级队列,定义一个初始化函数来完成:
1 | |
等待队列涉及三种操作,即入队,删除队列中的一个进程,以及取等待队列中最早到达的一个RUNNABLE的进程。
由于进程的优先级在运行过程中可能动态变化,所以可能要将一个进程从某个队列删除后添加到另一个队列中,这时,为了保持队列从到达时间早到晚排序,要遍历队列,找到该进程的插入位置。从最后(q->size-1)往前扫描,如果当前指针进程的到达时间ctime比新进程p->ctime大(晚),就把它往后挪。直到指向一个进程,到达时间<=p->ctime,然后把p插入到它的后面。最后,要将q->size增加一。
1 | |
删除队列的操作,是从前往后遍历该等待队列,找到要删除的进程,如果能找到,则将从该位置开始后面的进程都往前挪一个位置,最后一个位置变为0,最后把size减1.
1 | |
查找等待队列中第一个RUNNABLE的进程,只要从前往后遍历,找到第一个RUNNABLE的进程就返回即可。如果未找到,则返回0.
1 | |
接下来要就是要实现进程在执行过程中状态或优先级变化时相应的等待队列的操作。由于等待队列代价比较高,所以尽量在确定进程已经正确分配好各种资源,才将它加入到初始优先级队列中去。 在userinit中,设置默认优先级为2:
1 | |
在fork()中,让子进程继承父进程的优先级(默认为2),然后进入相应的等待队列:
1 | |
在进程终止,被父进程回收资源时,要将它们从相应的等待队列中删除,在wait和waitSch中作同样的改变:
1 | |
调度器的算法则跟之前较为不同。RR和静态优先级调度scheduler都是内循环遍历整个表,每次寻找最高优先级或第一个RUNNABLE进程进行调度,现在,静态多级反馈队列不用遍历整个表,它从最高优先级队列开始找起,如果某个队列里面有RUNNABLE的进程,就运行它,否则就往下一个优先级队列继续寻找:
1 | |
当调用set_priority时,有可能进程的优先级改变,则要将它从旧的优先级队列中删除并放到新的优先级队列中:
1 | |
多级反馈队列实现已经完成。将它编译,执行priority_sta.c,还是将子进程数目设置为4,得到如下输出:
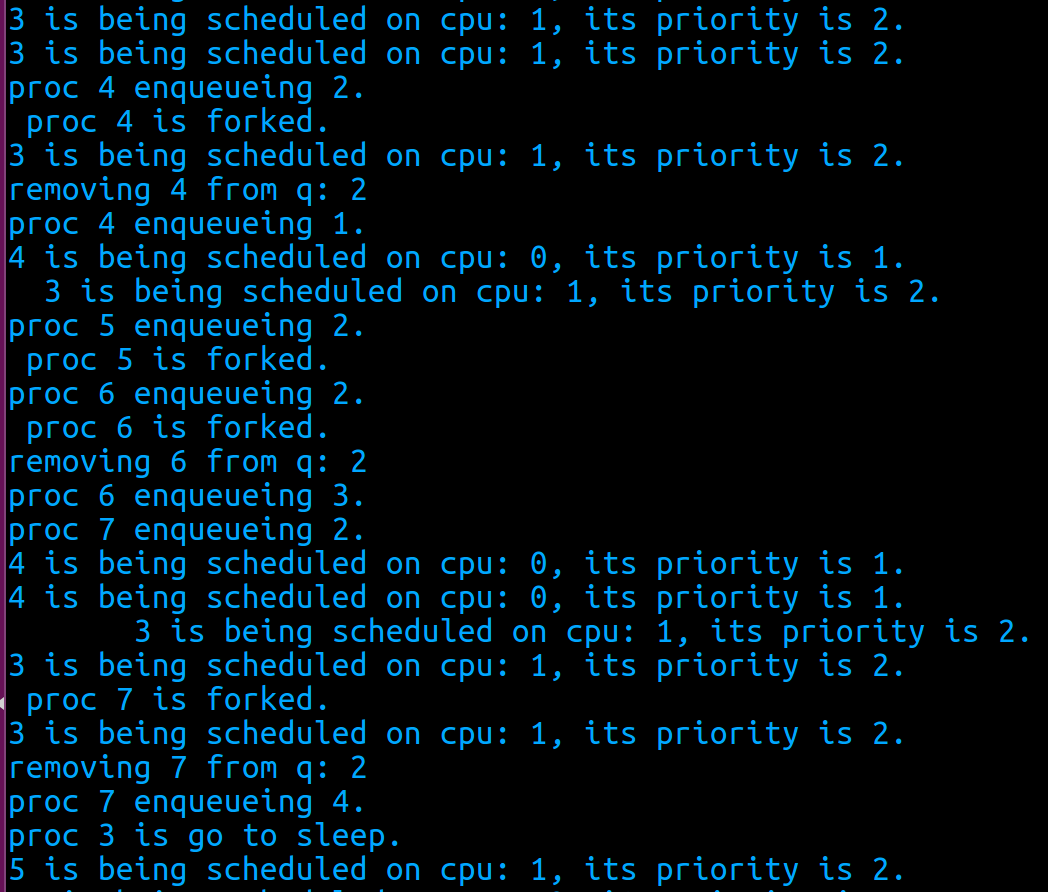
进程3是父进程,4,5,6,7分别是4个子进程,优先级被设置为1,2,3,4. 可以看到,每个进程在fork完成之前,都先进入了默认的第二优先级队列。当调用set_priority时,每个进程都从原来的queue 2离开,进入到相应新的队列中(进程5除外,进程5本来就在queue 2中)。当所有进程都创建好之后,因为3比5先到达,则只有进程3和4可以被调度;当进程3在倒数第二行进入休眠之后,进程5才可以得到调度。
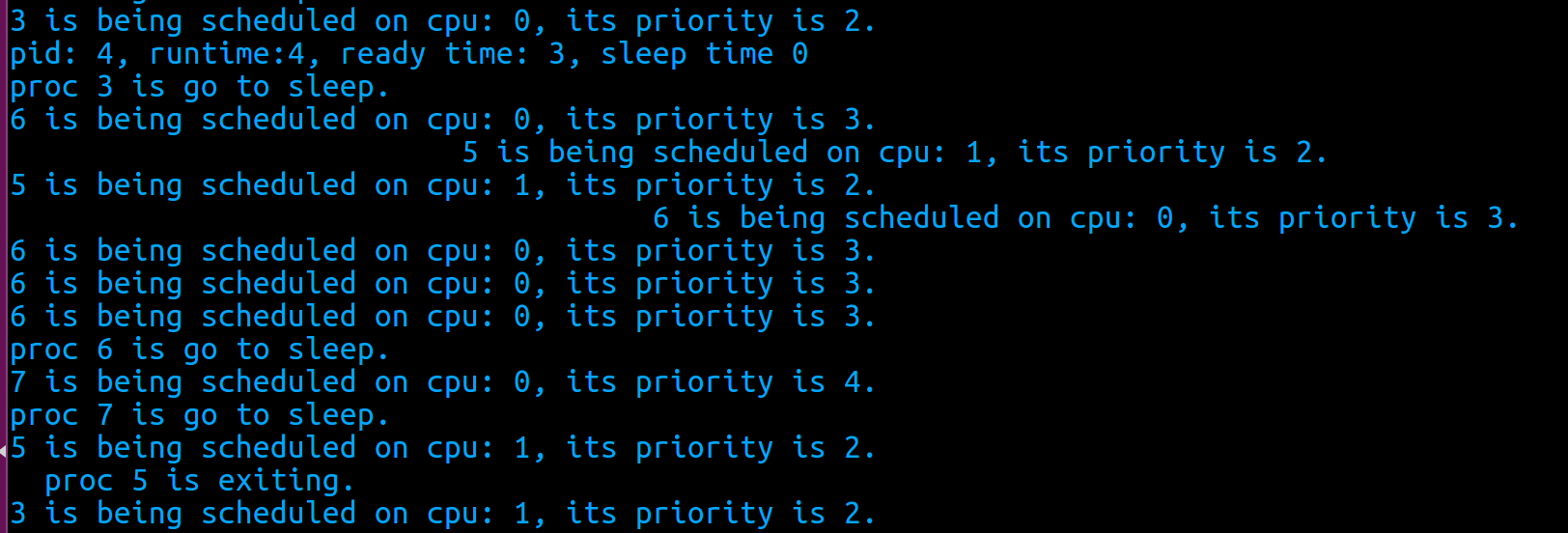
然后,等进程4退出并被回收了,它从queue 1中被删除。当进程3进入休眠的时候,进程5和6可以得到调度,在这整个过程中,进程7的优先级都不足,无法被调度。而当进程6进入休眠时,进程7才和5一起被调度。说明算法逻辑正确。
统计多级反馈下程序运行时间:
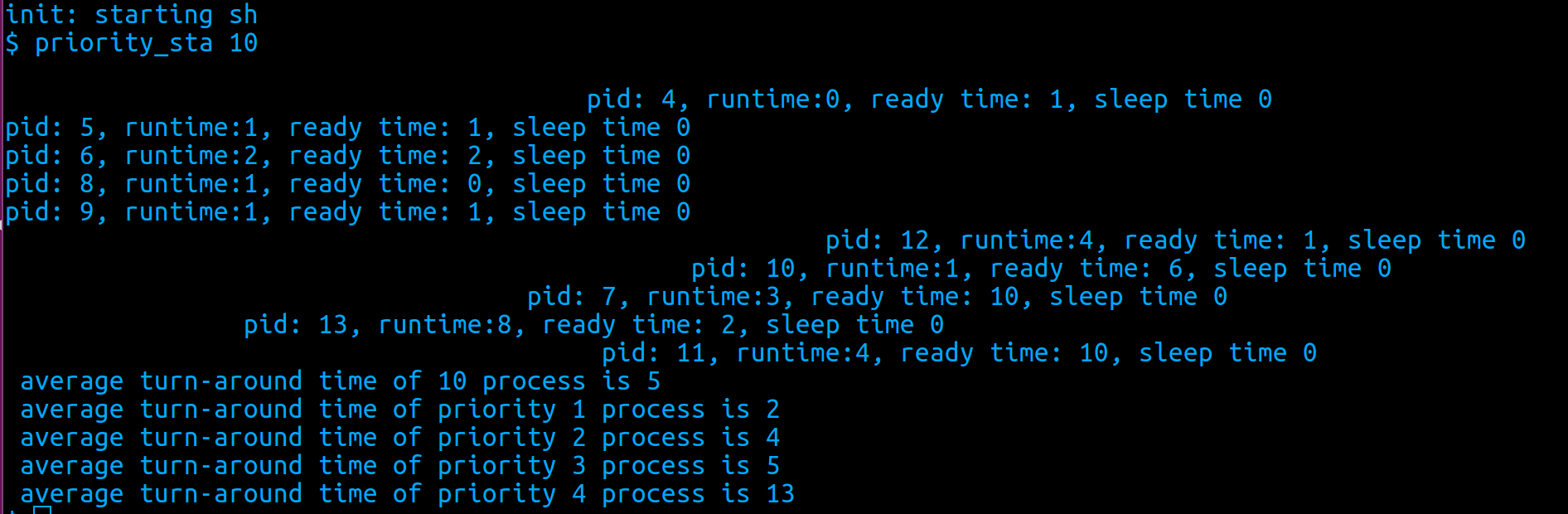
这个结果是符合预期的,如果程序执行的内容都一样,优先级越低,周转时间应该越长,因为更高优先级的进程应该更早被调度。
简单比较
比较所有进程的平均轮转时间:
| 进程个数 | RR | 静态优先级 | 多级反馈队列 |
|---|---|---|---|
| 4 | 6 | 4 | 4 |
| 10 | 8 | 4 | 7 |
| 30 | 15 | 10 | 17 |
(轮转时间的计算跟机器状态也有关系,有些时候机器运转较快,则用户程序的运行和调度算法都比较快,测得时间就会少)
如果忽略机器状况的因素,可以发现RR算法的平均轮转时间在进程个数一定时是多于静态优先级调度的。这是因为所有进程轮流调度,本来可以更早结束的进程时间被延长了;而静态优先级调度虽然低优先级的进程周转时间比平均长很多,但优先级高的进程周转时间也对应地低很多,并且如果先来先服务,高优先级进程基本上可以到达之后就一直进行直到结束,所以平均周转时间可能会更好。
但也要考虑算法的花销。在进程个数很多的时候,多级反馈队列每一次插入和删除的开销会快速增长,这导致进程的等待时间变得非常长。
为了缓解饥饿的问题,可以对优先级调度算法进行优化,采用动态的多级反馈队列:
-
进程刚开始时进入最高优先级队列。
- 不同的优先级队列中,进程有不同的时间片。优先级越高,时间片越短。这样,低优先级进程可以有更多机会完成任务。
- 每运行完一个/k个时间片,进程就下降优先级,最低优先级的进程反而重新回到最高优先级
这样做的好处是,进程刚开始创建优先级最高,可以有更快的响应时间;优先级随着进程运行下降,则可以偏向短作业,让短作业更快结束,从而缩短等待时间;每隔一段时间就将最低优先级的进程提高到高优先级,这样可以防止饥饿发生。
但是,动态多级反馈队列显然需要更多的算法花销,不同时间片的设计更为复杂,且需要设计每个优先级适当的时间片大小,以及按进程特性决定创建时进入哪个队列。即便如此,动态多级反馈队列仍然是一种比较优的算法。